
Back in 2015, Naughty Dog presented a talk about the various systems involved in the parallelization of their engine ( https://www.gdcvault.com/play/1022186/Parallelizing-the-Naughty-Dog-Engine). One thing that stood out in their presentation to me at the time was their implementation of a task system using fibers. I’ve always wanted to implement something similar and I’ve finally decided to get off my butt and try my hand at it!
Multitasking mechanisms
Fibers (or coroutines), like threads, are threads of execution. The key difference between the two is how execution is yielded to the thread scheduler. Fibers rely on cooperative multitasking while threads utilize preemptive multitasking.
Cooperative multitasking, as the name suggests, relies on threads of execution yielding control to the scheduler, at well defined points in code (usually with a yield statement or something similar). For multitasking to even work, threads must yield at some point or risk starving other threads of execution!
For completeness (though this isn’t really the focus of this post), preemptive multitasking relies on the underlying operating system determining when it is the best time for threads of execution to return control to the scheduler. This can happen during a call to sleep or randomly mid function.
Execution
A fiber is a thread of execution. Execution, at its very core, is the evaluation of logical statements.
At the hardware level, in the context of modern processing units, execution is implemented through the evaluation, using an instruction pointer (or program counter), of logical statements in the form of instructions. These instructions reside in memory and the instruction pointer points at the next instruction (in memory) to execute, getting incremented when evaluation occurs.
Execution state
Along with the instruction pointer (which stores the state of the next instruction to execute), the execution state of a program also includes general purpose registers, which hold values for instructions to operate on.

There are a fix number of registers so when there are more registers required than those that actually exist, programs utilize a block of last in first out memory called a stack, to temporarily push registers unto.
Furthermore, for more efficient use of instruction memory, reusable clusters of instructions are grouped together to form functions. Functions execute the same set of instructions given varying parameters. These parameters are passed into a function as arguments.
Because functions can be entered at different points of execution and must reliably return to those points after the function completes (usually with some form of result). Programs thus utilize the stack to also store these return points. In principle, when a function is called, all information needed to restore the current state of the program is pushed unto the stack (registers, including the instruction pointer, which is of itself a register). When the function completes execution, the state is popped from the stack and restored.
What is a fiber?
A fiber, being a thread of execution, implies that each fiber can be executed (execution) and the execution occurs independently (thread). Assuming our threads operate in a cooperative fashion, yielding is the action of switching from one thread of execution to another (i.e. switching from one fiber to another).
Since each fiber can execute independently, they require their own unique instruction pointer, pointing at the next instruction they are about to execute. They would also require their own set of registers, which are meaningful within the current context the fiber is executing in (i.e. the registers are assigned to/used as part of instruction evaluation of that particular fiber). Additionally, because each thread is executing independently they would require independent storage for execution state, maintaining a stack each for execution.
A fiber, in essence, therefore, exists in memory as a set of registers and a stack. Because the stack exists as as a block of addressable memory, the address of the top of the stack is normally also stored in a register (called the stack pointer). This simplifies the state of the fiber as just a set of registers. Together these form the thread’s context. When yielding from a fiber, by saving the context and restoring another fiber’s context, we pause the execution of the fiber we are yielding from and resume the execution of the other fiber we are transitioning to. If you are familiar with preemptive multitasking, this is the same context referred to when talking about “context switching“.
Implementation (x86)
Because fibers rely on low level hardware constructs like the instruction pointer and calling convention of functions (i.e. how functions use the stack when calls are made), implementation of fibers can differ from platform to platform.
For the purposes of this post, I look at how functions are implemented in x86 assembly (the instruction set of arguably one of the most widespread processor architectures). I also hope to target ARM at some point in the not too distant future, so an ARM implementation feature in one of my subsequent posts.
Context
As mentioned earlier, a context is simply a set of registers, one of which being the stack pointer. While we could store this set of registers in the context (and often fiber implementations do this for efficiency), we will simplify our context by storing all the registers on the stack and keeping only the stack pointer in the context (more on this later).
Our simplified context looks like this:
struct Context
{
intptr_t m_StackPointer;
};
Fiber
The fiber class represents a fiber, holding initialization parameters (entry point) and the runtime state (stack and context). We also store the fiber’s current lifecycle state, which allows us to know when we are scheduling fibers that have not yet started and to prevent us from scheduling fibers that have completed execution. We also define a global pool of fibers which we will schedule out of.
const unsigned STACK_SIZE = 65536;
// ...
struct Fiber
{
Context m_Context;
std::function<void()> m_EntryPoint;
uint8_t m_Stack[STACK_SIZE];
struct State
{
enum Enum
{
None,
Started,
Ended
};
};
State::Enum m_State;
};
static std::vector< std::shared_ptr<Fiber> > g_Fibers;
We construct fibers by setting up a context with a stack pointer pointing to the fiber’s stack. We also define the fiber’s starting state as None signifying that it has not been started before.
std::shared_ptr<Fiber> CreateFiber(std::function<void()> entryPoint)
{
auto fiber = std::make_shared<Fiber>();
fiber->m_Context.m_StackPointer = (intptr_t)&fiber->m_Stack[STACK_SIZE - 1];
fiber->m_EntryPoint = entryPoint;
fiber->m_State = Fiber::State::None;
std::memset(fiber->m_Stack, 0, sizeof(fiber->m_Stack));
return fiber;
}
Context Switching
To switch from one thread to another, we’ll make use of two properties of the stack. First, that the stack stores the calling address for functions to return to after execution (as discussed above) and that the stack can be used to hold the contents of registers so that we can reduce our context in memory to a single stack pointer and use the stack to store all other pointers.
Our context switch mechanism will therefore be a function, that enters from one thread of execution, but leaves into another thread of execution.
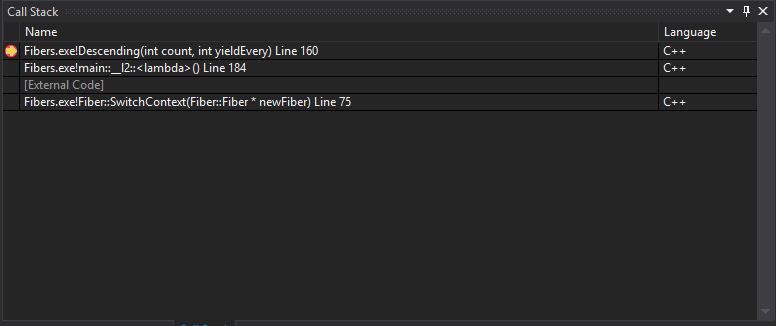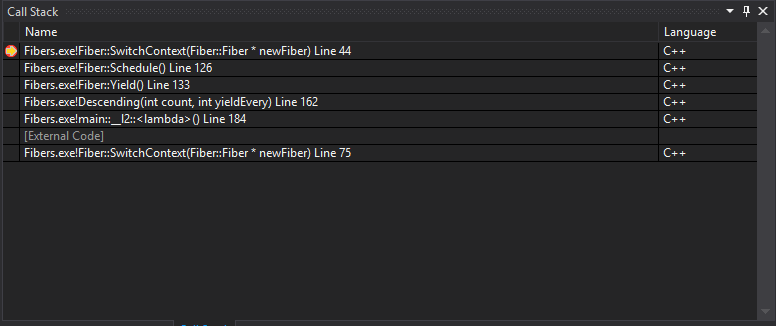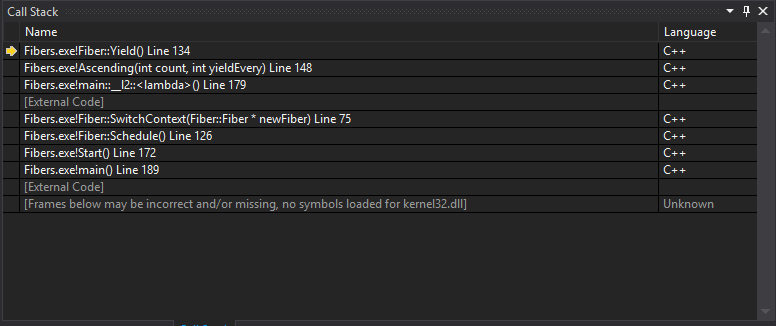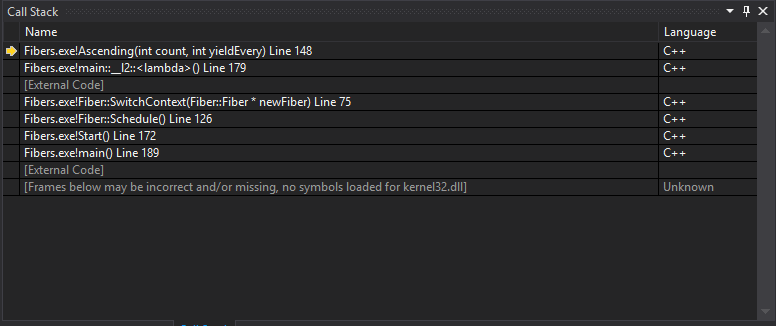
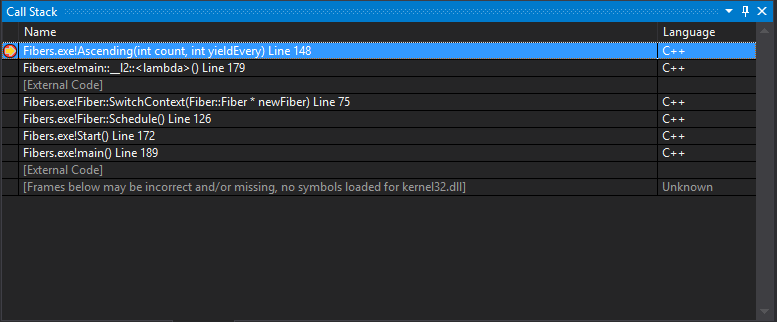
In it’s simplest form:
void SwitchContext(Fiber* newFiber)
{
// save current context
uintptr_t stackPointer;
_asm
{
pushad;
mov stackPointer, esp;
}
g_CurrentContext->m_StackPointer = stackPointer;
g_CurrentContext = newFiber ? &newFiber->m_Context : &g_MainContext;
stackPointer = g_CurrentContext->m_StackPointer;
// switch stack
_asm
{
mov esp, stackPointer;
popad;
}
}
This works if the fiber we are switching into has already started execution and context switched at some point. But for fibers that have yet to start, the function would be the first function on the callstack (and therefore have no address to return to). We therefore need to add support for starting fibers, which is why the fiber’s state comes in handy.
void SwitchContext(Fiber* newFiber)
{
// save current context
uintptr_t stackPointer;
_asm
{
pushad;
mov stackPointer, esp;
}
g_CurrentContext->m_StackPointer = stackPointer;
g_CurrentContext = newFiber ? &newFiber->m_Context : &g_MainContext;
stackPointer = g_CurrentContext->m_StackPointer;
// switch stack
_asm
{
mov esp, stackPointer;
}
if (newFiber && newFiber->m_State == Fiber::State::None)
{
// keep the fiber pointer on the stack so we can get it later
_asm
{
mov eax, newFiber;
push eax;
}
newFiber->m_State = Fiber::State::Started;
newFiber->m_EntryPoint();
_asm
{
pop eax;
mov newFiber, eax;
}
newFiber->m_State = Fiber::State::Ended;
Schedule(); // leave this fiber behind
}
// restore context
_asm
{
popad;
}
}
Scheduling
You might have noticed that from the last code snippet, after the execution of a fiber, the Schedule function was called. Scheduling serves the purpose of choosing the next fiber to context switch into and is the function that is called when a fiber yields (or in the case above, completes execution).
Scheduling, in and of itself, is a large and potentially complex topic that I won’t go into too much detail here. For our purposes, I use a simple round robin scheduling that ensures that threads have a fair opportunity to execute by sequentially iterating fibers and scheduling them one after the other if they have not completed execution.
When all fibers have completed execution, execution is returned to the calling thread’s context (before any fiber execution occurred), by passing nullptr into SwitchContext.
void Schedule()
{
// Simple scheduler that just round robins the fibers
static unsigned nextFiberToSchedule = 0;
unsigned fiberToSchedule = g_Fibers.size();
for (unsigned i = 0; i < g_Fibers.size(); ++i)
{
unsigned currentFiberIndex = (nextFiberToSchedule + i) % g_Fibers.size();
if (g_Fibers[currentFiberIndex]->m_State == Fiber::State::Ended)
continue;
fiberToSchedule = currentFiberIndex;
break;
}
// By default switch to the main context
Fiber* newFiber = nullptr;
// If we have anything left to schedule, schedule that first
if (fiberToSchedule != g_Fibers.size())
{
// Update next fiber to schedule
nextFiberToSchedule = (fiberToSchedule + 1) % g_Fibers.size();
newFiber = g_Fibers[fiberToSchedule].get();
}
// Perform the actual context switch
SwitchContext(newFiber);
}
Conclusion
That pretty much covers the basics of cooperative multitasking. While there are certainly more efficient ways to implement fibers, this should provide a pretty clear idea of how they work.
If you’d like to compile and try out the source above, I’ve written a quick example Visual Studio solution.